Reverse Engineering: Theory
While transparency faces a number of challenges as an effective check on algorithmic power, an alternative and complementary approach is emerging based around the idea of reverse engineering how algorithms are built. Reverse engineering is the process of articulating the specifications of a system through a rigorous examination drawing on domain knowledge, observation, and deduction to unearth a model of how that system works. It’s “the process of extracting the knowledge or design blueprints from any- thing man-made.”23
Some algorithmic power may be exerted intentionally, while other aspects might be incidental. The inadvertent variety will benefit from reverse engineering’s ability to help characterize unintended side effects. Because the process focuses on the system’s performance in-use it can tease out con- sequences that might not be apparent even if you spoke directly to the designers of the algorithm. On the other hand, talking to a system’s designers can also uncover useful information: design decisions, descriptions of the objectives, constraints, and business rules embedded in the system, major changes that have happened over time, as well as implementation details that might be relevant.24,25 For this reason, I would advocate that journalists engage in algorithmic accountability not just through reverse engineering but also by using reporting techniques, such as interviews or document reviews, and digging deep into the motives and design intentions behind algorithms.
Algorithms are often described as black boxes, their complexity and technical opacity hiding and obfuscating their inner workings. At the same time, algorithms must always have an input and output; the black box actually has two little openings. We can take advantage of those inputs and outputs to reverse engineer what’s going on inside. If you vary the inputs in enough ways and pay close attention to the outputs, you can start piecing together a theory, or at least a story, of how the algorithm works, including how it transforms each input into an output, and what kinds of inputs it’s using. We don’t necessarily need to understand the code of the algorithm to start surmising something about how the algorithm works in practice.
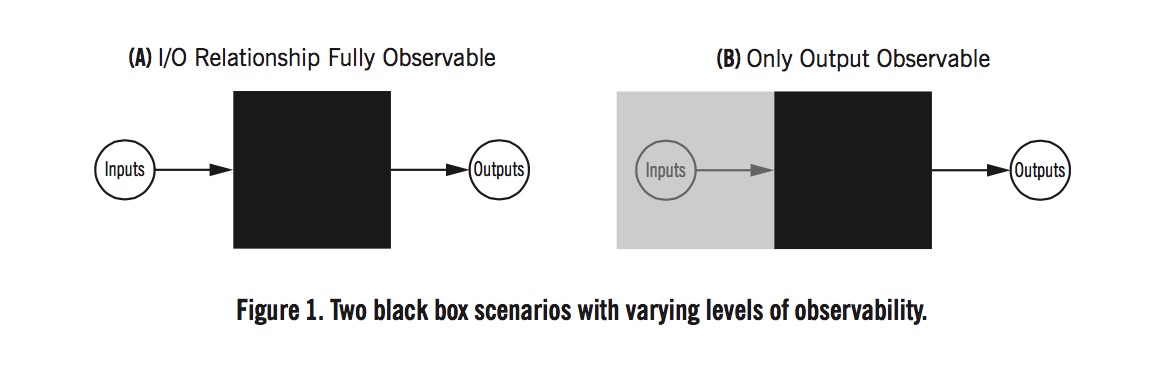
image
Figure 1 depicts two different black-box scenarios of interest to journalists reverse engineering algorithms by looking at the input-output relationship. The first scenario, in Figure 1(A), corresponds to an ability to fully observe all of an algorithm’s inputs and outputs. This is the case for algorithms accessible via an online API, which facilitates sending different inputs to the algorithm and directly recording the output.
Figure 1(B) depicts a scenario in which only the outputs of the algorithm are visible. The value-added model used in educational rankings of teachers is an example of this case. The teacher rankings themselves became available via a FOIA request, but the inputs to the algorithm used to rank teachers were still not observable. This is the most common case that data journalists encounter: A large dataset is available but there is limited (or no) information about how that data was transformed algorithmically. Interviews and document investigation are especially important here in order to understand what was fed into the algorithm, in terms of data, parameters, and ways in which the algorithm is used. It could be an interesting test of existing FOIA laws to examine the extent to which unobservable algorithmic inputs can be made visible through document or data requests for transparency.
Sometimes inputs can be partially observable but not controllable; for instance, when an algorithm is being driven off public data but it’s not clear exactly what aspect of that data serves as inputs into the algorithm. In general, the observability of the inputs and outputs is a limitation and challenge to the use of reverse engineering in practice. There are many algorithms that are not public facing, used behind an organizational barrier that makes them difficult to prod. In such cases, partial observability (e.g., of outputs) through FOIA, Web-scraping, or something like crowdsourcing can still lead to some interesting results.